RL02 CSV Reader
Outline
The CSV Data and Log Reader is a configurable reader for all typical kinds of CSV (Comma-Separated Values) based data and log formats. CSV is a common data exchange format that is widely supported by consumer, business, and scientific applications. With easy to use dialogs you can define configurations (separators, first line, labels, data types,...) for your specific formats. This article will help you configure and use the reader.
| Platforms: |
|
|||
| Requirements: |
|
|||
| Known limitations: |
|
|||
| Status: |
|
|||
| Operations: |
|
|||
| Default Parameters: |
|
|||
| Configuration: |
|
 32/64bit
32/64bit 32/64bit
32/64bit 32/64bit
32/64bitAbout Comma-separated values
A comma-separated values (CSV) file stores tabular data (numbers and text) in plain text. Each line of the file is a data set. Each set consists of one or more fields, separated by commas or other delimiters. The top line may contain labels, associated with the fields.Here a typical example:
time;osc_out;lvdt_outp;lvdt_outn 0;0;0;0 1.19209e-07;0.364121124438;0.361954160418;-0.361960938184 2.38418e-07;0.549114671567;0.544246145289;-0.544266588099 3.57627e-07;0.496353600022;0.488405852023;-0.488433470485 4.76836e-07;0.488886165659;0.478050306956;-0.478086469891
Beside data you also find CSV files with logs:
0,1587458274777,TRACE,11,ThreadA,5," No Local Variables are initialized for Method [_GTF",org.apache.logging.log4j.spi.AbstractLogger,de.toem.impulse.test.primary.Log1,,,de.toem.impulse.test.AbstractLog.log(AbstractLog.java:630),{},[]
0,1587458274887,WARN,11,ThreadA,5,get Sinus Wave -0.004940748208935772,org.apache.logging.log4j.spi.AbstractLogger,de.toem.impulse.test.secondary.Log3,,,de.toem.impulse.test.secondary.Log3.log(Log3.java:18),{},[]
0,1587458274898,DEBUG,12,ThreadB,5,get Sinus Wave 0.04504322352107653,org.apache.logging.log4j.spi.AbstractLogger,de.toem.impulse.test.secondary.Log3,,,de.toem.impulse.test.secondary.Log3.log(Log3.java:18),{},[]
0,1587458274900,INFO,1,main,5," ACPI: Local APIC address 0xfee00000",org.apache.logging.log4j.spi.AbstractLogger,de.toem.impulse.test.primary.Log1,,,de.toem.impulse.test.AbstractLog.log(AbstractLog.java:630),{},[]
Usage
The reader can be used to open workspace resources and together with ports (direct connection to the target using TCP, Serial, J-Link, ...).
Content type association

To use a reader for a given input resource,
- a valid content type association needs to be in place,
- and the reader need to identify the file resource content as valid data (Content detection).
The serializer dialog contains the field "Content type association" with which you can manage file associations (e.g. to add "*.log" as a valid file name).
Content type association is only meaningful for eclipse resources, not for port inputs like TCP oder File/Pipe ports.
Content Detection and Configurations
This reader requires a reader configuration to work. Such a configuration defines the form of the input content and how it shall be read.
Typically a reader has several configurations that can be enabled or disabled.
The reader does a content type detection to:
- identify if the content is valid and matches a given configuration,
- or to select a valid configuration for the given input, if not done explicitly by the user ("Default" selection).
A file resource has valid content data if at least 1 enabled configuration matches.
Configuration
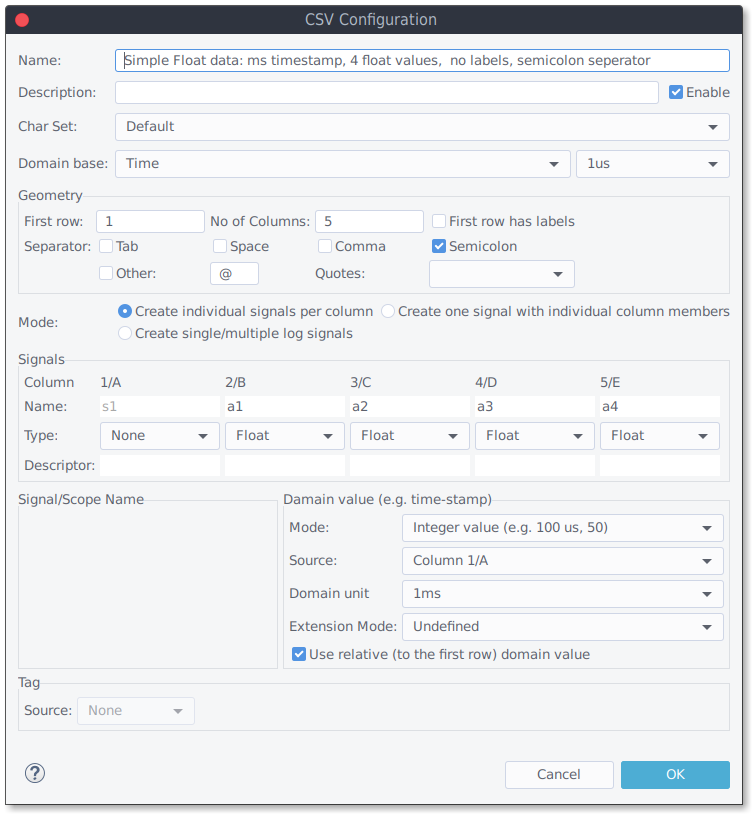
The CSV Reader requires a configuration (CSV Configuration) to work. A configuration contains information about the char set, the delimiter, labels and and the actual data fields. Press "Add" and select "CSV Configuration" to create a new reader configuration:
- Char Set: Select the char set that is used by the log file (or "Default").
- Domain Base: Select the domain base. This represents is smallest domain change (e.g. 1 ms).
- Updates: This reader has some sample or standard configurations after installation. After an update of impulse, these configurations may also have been updated. To exclude a configuration from updating (e.g. because you have adapted the configuration for your application), you can set the flag "Do not update with latest version".
- First row: Indicated the first row (starting with 1) of data or labels field.
- No of columns: No of expected columns. If the no of columns is smaller than expected, an error will be thrown.
- First row has labels: Check if the first row contains labels. These labels will be used to name the generated signals or members. If not given, standard names (s1 ,s2,..) will be taken.
- Separator: The character to splits data and label fields.
- Quote: Select if your content uses double-, single- or no quote meta-characters. Quotes are used to enclose text content with separator characters or quotes.
- Mode:Select if the reader shall create a signal for each data column, or one struct signal with a member for each data column or log signals.
Mode 0: Create individual signals per column
This mode is a typical data mode. Each configured column will create a signal of a given type. The signal name comes either from a label in the input or the configuration.
Name and configure the signals

Select member names and types for all columns that shall create a signal.
- Type in the member names. If you leave the field blank, either a standard name is taken (e.g. s1) or an optional label defines the signal name.
- Define the member type and a descriptor.
Valid member types are:
- Float,
- Integer,
- Text ,
- or Enumeration.
The descriptor field can optionally contain a content or signal descriptor:
- a simple content descriptor e.g. "default", "state", event" or "label", ...
- a complete signal descriptor e.g. "default<df=Hex>" or "state<df=Text>"
Mode 2: Create one signal with individual column members
This mode create only 1 struct signal. Each configured column will create a member of a given type. The member name comes either from a label in the input or the configuration.
Name and configure the members

Select member names and types for all columns that shall create a signal.
- Type in the member names. If you leave the field blank, either a standard name is taken (e.g. s1) or an optional label defines the signal name.
- Define the member type and a descriptor.
Valid member types are:
- Float,
- Integer,
- Text ,
- or Enumeration.
The descriptor field can optionally contain a content or member descriptor:
- a simple content descriptor e.g. "default", "state", event" or "label", ...
- a complete member descriptor e.g. "default<df=Hex>" or "state<df=Text>"
Mode 3: Create single/multiple log signals
The mode handles the csv input as a log. Depending on the naming scheme, 1 or log signals will be created .
Name and configure the sample members

Log signals are struct signal with multiple members.
Select member names and types for all columns that shall have a member in you log samples (e.g. the message).
- Select the member names. You can select a predefined member names or enter custom ones.
- For custom members you can define the member type and a descriptor.
Valid member types are:
- Float,
- Integer,
- Text ,
- or Enumeration.
The descriptor field can optionally contain a content or member descriptor:
- a simple content descriptor e.g. "default", "state", event" or "label", ...
- a complete member descriptor e.g. "default<df=Hex>" or "state<df=Text>"
Define the signal naming scheme

Each single sample belongs to one signal. You can organize your samples into one or multiple signals (e.g. a signal per log source). The "Signal/Scope name" section allows to select the signal and scope naming scheme for each log element.
- Undefined : All log samples get into one signal with the name "log".
- Explicit name : Define a signal name for all samples.
- Explicit hierarchy : Define a signal/scope hierarchy for all samples. The signal and scope names are generated by splitting the value into its contents (e.g. the value "de.toem.logger" creates the scope/signal hierarchy de/toem/logger).
- Name from source value : The value of the selected column is taken to define the signal name (.e.g. from the logger source).
- Hierarchy from source value : The value of the selected column is taken to define the signal and scope names by splitting the value into its contents (e.g. the value "de.toem.logger" creates the scope/signal hierarchy de/toem/logger).
You may extend the naming scheme with another column value. If enabled, the value of the source will be put after the signal name (in parentheses).
Set the tag source and identification patterns
Add log tags (Fatal, Error, Warning, Success, Info, Debug, Trace) to all samples. The tag modifies the presentation color and can be made visible in the complementary views. The tag patterns are regular expressions. A typical expression for the "Error" tag could be "error|Error|ERR".
All modes: Configure the domain value source and format (usually the time-stamp)
- Date: You need to define the date format. Use the content proposals and http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html. The parsing of the date value results into milliseconds after January 1, 1970 00:00:00 GMT.
- Float domain value: Parse a float value, optionally parse the domain unit from the source value or assign a unit.
- Integer domain value: Parse an integer value, optionally parse the domain unit from the source value or assign a unit.
There may be CSV logs without a domain value. In this case you may want to use:
- Incrementing: Increment the domain value with every new sample (all signals).
- Incrementing (per Signal): Increment the domain value with every new sample per signals.
- Reception time: Use the current time in milliseconds after January 1, 1970 00:00:00 GMT as domain value.
You may extend the domain position with another column value (e.g one column contains the seconds, another nanoseconds):
- Undefined : Do not extend.
- Float domain value: Parse a float value, optionally parse the domain unit from the source value or assign a unit. The domain extension value will be added to the main domain position.
- Integer domain value: Parse an integer value, optionally parse the domain unit from the source value or assign a unit. The domain extension value will be added to the main domain position.
Date formats are specified by date and time pattern strings:
G |
Era designator | Text | AD |
y |
Year | Year | 1996; 96 |
M |
Month in year | July; Jul; 07 |
|
w |
Week in year | 27 |
|
W |
Week in month | 2 |
|
D |
Day in year | 189 |
|
d |
Day in month | 10 |
|
F |
Day of week in month | 2 |
|
E |
Day in week | Text | Tuesday; Tue |
a |
Am/pm marker | Text | PM |
H |
Hour in day (0-23) | 0 |
|
k |
Hour in day (1-24) | 24 |
|
K |
Hour in am/pm (0-11) | 0 |
|
h |
Hour in am/pm (1-12) | 12 |
|
m |
Minute in hour | 30 |
|
s |
Second in minute | 55 |
|
S |
Millisecond | 978 |
|
z |
Time zone | General time zone | Pacific Standard Time; PST; GMT-08:00 |
Z |
Time zone | RFC 822 time zone | -0800 |
Parse errors
The reader will provide a parse error message if the input can not be read. The message usually contains the error position, the reason for the failure and a stack trace.
If you can not resolve the problem (e.g. obvious format error in the input file), please send this message together with the input file to "This email address is being protected from spambots. You need JavaScript enabled to view it.".
Reader: de.toem.impulse.serializer.csv
Error at position: 0
Text at position: "0,1587458274777,TRACE,11,ThreadA,5," No Local Variables are initialized for Method [_GTF",org.apache.logging.log4j.spi.AbstractLogger,de.toem.impulse.test.primary.Log1,,,de.toem.impulse.test.AbstractLog.log(AbstractLog.java:630),{},[]"
Message: Invalid no of values
Type: class de.toem.impulse.serializer.ParseException
Stack trace:
de.toem.impulse.extension.log.csv.CsvReader.handleLine(CsvReader.java:529)
de.toem.impulse.extension.log.csv.CsvReader.parse(CsvReader.java:495)
de.toem.impulse.serializer.AbstractParsingRecordReader.read(AbstractParsingRecordReader.java:117)
de.toem.impulse.serializer.AbstractRecordReader.read(AbstractRecordReader.java:204)
de.toem.pattern.element.Element$1.execute(Element.java:1067)
de.toem.eclipse.hooks.actives.EclipseActives$3.run(EclipseActives.java:73)