RL03 XML Log Reader
Outline
The XML Log Reader is a configurable log reader for all kinds of XML (Extensible Markup Language) based log formats and comes with pre-defined Log4J (1.2&2) and Java logging configurations. A powerful UI helps to define and extend reader configurations.
| Platforms: |
|
|||
| Requirements: |
|
|||
| Known limitations: |
|
|||
| Status: |
|
|||
| Operations: |
|
|||
| Parameters: |
|
|||
| Configuration: |
|
|||
| Tutorials: |
 32/64bit
32/64bit 32/64bit
32/64bit 32/64bit
32/64bitAbout XML logs
There is no standard XML log format existing. Various formats pack the log data into different text elements or attributes. Additionally, some formats use well-formed XML, others have XML fragments.
Here a 2 typical log examples, first the fragmented "Log4J 1.2"" and second the "Java logging format":
<log4j:event logger="de.toem.impulse.test.primary.Log1" timestamp="1587458274777" level="TRACE" thread="ThreadA"> <log4j:message><![CDATA[ No Local Variables are initialized for Method [_GTF]]></log4j:message> </log4j:event>
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <!DOCTYPE log SYSTEM "logger.dtd"> <log> <record> <date>2009-12-09T10:04:57</date> <millis>1260371097880</millis> <sequence>0</sequence> <logger>com.sun.deploy</logger> <level>FINE</level> <class>com.sun.deploy.util.LoggerTraceListener</class> <method>print</method> <thread>10</thread> <message>Reading certificates from 11108 http://pub.admc.com/modeler/modeler-pro.jar | /home/blaine/.java/deployment/cache/6.0/36/363eb424-1a174301.idx </message> </record>
Usage
The reader can be used to open workspace resources and together with ports (direct connection to the target using TCP, Serial, J-Link, ...).
Content type association
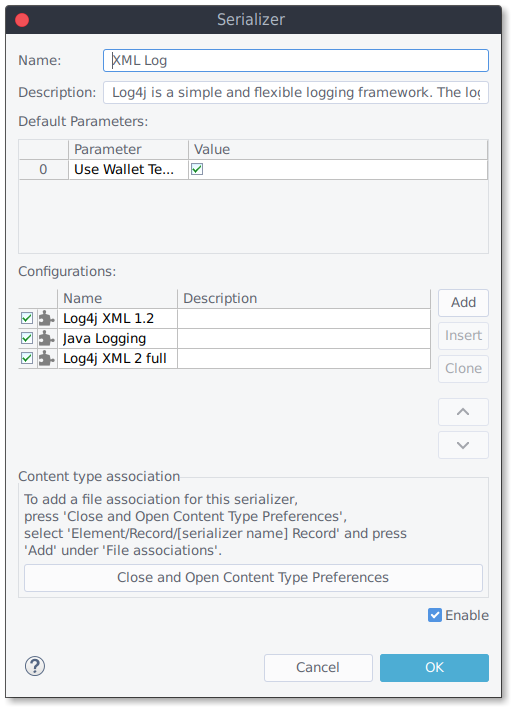
To use a reader for a given input resource,
- a valid content type association needs to be in place,
- and the reader need to identify the file resource content as valid data (Content detection).
The serializer dialog contains the field "Content type association" with which you can manage file associations (e.g. to add "*.log" as a valid file name).
Content type association is only meaningful for eclipse resources, not for port inputs like TCP oder File/Pipe ports.
Content Detection and Configurations
This reader requires a reader configuration to work. Such a configuration defines the form of the input content and how it shall be read.
Typically a reader has several configurations that can be enabled or disabled.
The reader does a content type detection to:
- identify if the content is valid and matches a given configuration,
- or to select a valid configuration for the given input, if not done explicitly by the user ("Default" selection).
A file resource has valid content data if at least 1 enabled configuration matches.
Configuration
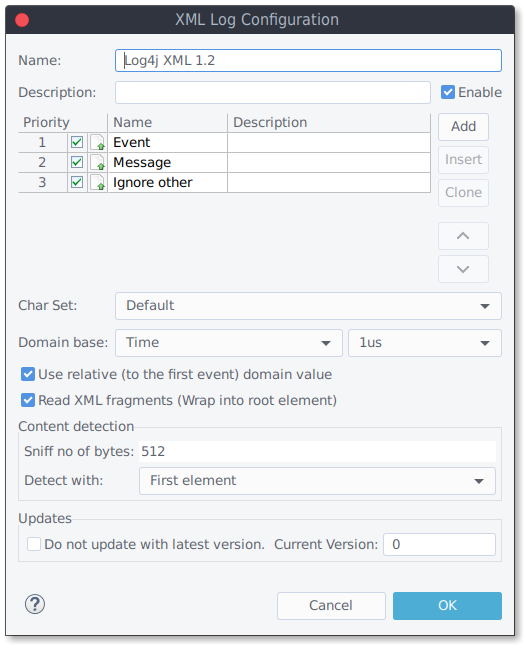
The XML Log Reader requires a configuration (XML Log Configuration) to work. Each configuration contains a set of log elements. Each log element describes the form and content of a single XML element.
Click the "Add" button to add a new "XML Log Configuration"" and fill in the following parameters:
- Char Set: Select the char set that is used by the log file (or "Default").
- Domain Base: Select the domain base. This represents is smallest domain change (e.g. 1 ms).
- Use relative domain value: Check to convert absolute domain values of the input into relative one (relative to the first domain position).
- Read XML fragments: If checked, the reader will wrap the input content into a dummy root element.
- Content detection: This setting defines one of your log elements as the one used for content detection. If the specified log element matches with one of the first elements of an input, the configuration is considered valid. You can also specify how many bytes (from the beginning of the input) to use for content detection. A log element matches, if the element path/name matches and at least half of the defined attributes can be found in that element.
- Updates: This reader has some sample or standard configurations after installation. After an update of impulse, these configurations may also have been updated. To exclude a configuration from updating (e.g. because you have adapted the configuration for your application), you can set the flag "Do not update with latest version".
A log element describes the form and content of a single XML element (element name and path, attributes and text content).
You may define multiple log elements:
- if you encounter multiple hierarchical XML elements that form a log entry (which is usually the case),
- or to ignore certain elements. It is often useful to add a log element with the element name "*" and the action "Ignore" on lowest priority to ignore all elements that do not match a valid log element (e.g. a root element) and thus avoid parse errors.
When reading an input, the reader takes the first log element that matches. Use the buttons on the right side to re-order the priority of your log elements. If no log element matches a found XML element, a parse error will be thrown.
Log Element
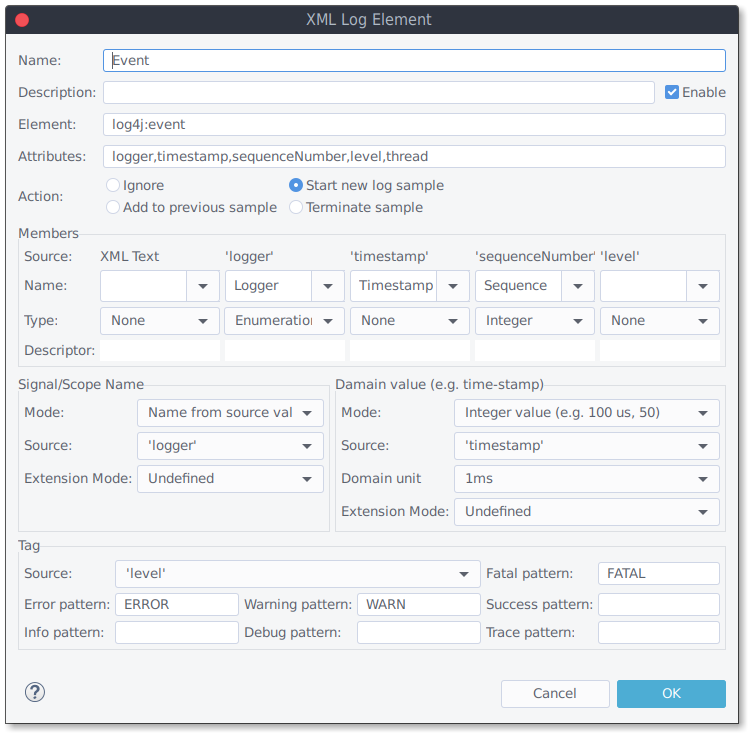
Press "Add" and select "Log Element" to create a new log element.
A log element describes the form and content of one single XML element (element name/path, attributes and text content).
Define the XML element path and attributes
The dialogue starts with the following fields:
- Element: Enter the name or the path of the element (e.g. record/millis or just millies). Enter "*" for any element (e.g. "record/*" for any element below 'record').
- Attributes: Add a comma separated list of attributes of the XML element.
All attributes that are not listed are ignored. If listed attributes do not occur in an XML element, an error is only thrown if the value is required for domain value calculation.
After this first step is done, you need to define how to use the element and its extracted text and attributes.
Select the action
- Ignore : Just skip this element;
- Start new log sample;
- Add to previous sample: The information of the sources (attributes and text) will be added to the previously started sample (to handle hierarchical elements). A new sample will be started if no previous is available;
- Finish sample: The information of the sources will be added to the previously started sample. Afterwards the sample will be finished (Additional elements can not be added).
Name and configure the sample members

Log signals are struct signal with multiple members.
Select member names and types for all sources (text and attributes) that shall have a member in you log samples (e.g. the message).
- Select the member names. You can select a predefined member names or enter custom ones.
- For custom members you can define the member type and a descriptor. If custom members are used over multiple elements, the type need to be identical.
Valid member types are:
- Float,
- Integer,
- Text ,
- or Enumeration.
The descriptor field can optionally contain a content or member descriptor:
- a simple content descriptor e.g. "default", "state", event" or "label", ...
- a complete member descriptor e.g. "default<df=Hex>" or "state<df=Text>"
Define the signal naming scheme

Each single sample belongs to one signal. You can organize your samples into one or multiple signals (e.g. a signal per log source). The "Signal/Scope name" section allows to select the signal and scope naming scheme for each log element.
- Undefined : Either all log samples get into one signal with the name "log" -- or this log element is part of a hierarchical multi-element log and the name information is not part of this element.
- Explicit name : Define a signal name for all samples of this log element.
- Explicit hierarchy : Define a signal/scope hierarchy for all samples of this log element. The signal and scope names are generated by splitting the value into its contents (e.g. the value "de.toem.logger" creates the scope/signal hierarchy de/toem/logger).
- Name from source value : The value of the selected source is taken to define the signal name (.e.g. from the logger source).
- Hierarchy from source value : The value of the selected source is taken to define the signal and scope names by splitting the value into its contents (e.g. the value "de.toem.logger" creates the scope/signal hierarchy de/toem/logger).
You may extend the naming scheme with another source value. If enabled, the value of the source will be put after the signal name (in parentheses).
Configure the domain value source and format (usually the time-stamp)
- Undefined : In case of hierarchical multi-element logs, you will have elements without domain information.
- Date: You need to define the date format. Use the content proposals and http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html. The parsing of the date value results into milliseconds after January 1, 1970 00:00:00 GMT.
- Float domain value: Parse a float value, optionally parse the domain unit from the source value or assign a unit.
- Integer domain value: Parse an integer value, optionally parse the domain unit from the source value or assign a unit.
There may be log elements without a domain value. In this case you may want to use:
- Same as previous: Use the domain value of the previous sample (all signals).
- Same as previous (per Signal): Use the domain value of the previous sample of the used signal.
- Incrementing: Increment the domain value with every new sample (all signals).
- Incrementing (per Signal): Increment the domain value with every new sample per signals.
- Reception time: Use the current time in milliseconds after January 1, 1970 00:00:00 GMT as domain value.
You may extend the domain position with another source value (e.g one attribute contains the seconds, another nanoseconds):
- Undefined : Do not extend.
- Float domain value: Parse a float value, optionally parse the domain unit from the source value or assign a unit. The domain extension value will be added to the main domain position.
- Integer domain value: Parse an integer value, optionally parse the domain unit from the source value or assign a unit. The domain extension value will be added to the main domain position.
Date formats are specified by date and time pattern strings:
G |
Era designator | Text | AD |
y |
Year | Year | 1996; 96 |
M |
Month in year | July; Jul; 07 |
|
w |
Week in year | 27 |
|
W |
Week in month | 2 |
|
D |
Day in year | 189 |
|
d |
Day in month | 10 |
|
F |
Day of week in month | 2 |
|
E |
Day in week | Text | Tuesday; Tue |
a |
Am/pm marker | Text | PM |
H |
Hour in day (0-23) | 0 |
|
k |
Hour in day (1-24) | 24 |
|
K |
Hour in am/pm (0-11) | 0 |
|
h |
Hour in am/pm (1-12) | 12 |
|
m |
Minute in hour | 30 |
|
s |
Second in minute | 55 |
|
S |
Millisecond | 978 |
|
z |
Time zone | General time zone | Pacific Standard Time; PST; GMT-08:00 |
Z |
Time zone | RFC 822 time zone | -0800 |
Set the tag source and identification patterns
Add log tags (Fatal, Error, Warning, Success, Info, Debug, Trace) to all samples. The tag modifies the presentation color and can be made visible in the complementary views. The tag patterns are regular expressions. A typical expression for the "Error" tag could be "error|Error|ERR".
Parse errors
The reader will provide a parse error message if the input can not be read. The message usually contains the error position, the reason for the failure and a stack trace.
If you can not resolve the problem (e.g. obvious format error in the input file), please send this message together with the input file to "This email address is being protected from spambots. You need JavaScript enabled to view it.".
Reader: de.toem.impulse.serializer.log.xml Message: Markup im Dokument nach dem Root-Element muss ordnungsgemäß formatiert sein. Type: class org.xml.sax.SAXParseException Stack trace: com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(ErrorHandlerWrapper.java:203) com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.fatalError(ErrorHandlerWrapper.java:177) com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(XMLErrorReporter.java:400) com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(XMLErrorReporter.java:327) com.sun.org.apache.xerces.internal.impl.XMLScanner.reportFatalError(XMLScanner.java:1472) com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl$TrailingMiscDriver.next(XMLDocumentScannerImpl.java:1395) com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:602) com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:505) com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:842) com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:771) com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:141) com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1213) com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:643) com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl.parse(SAXParserImpl.java:327) javax.xml.parsers.SAXParser.parse(SAXParser.java:195) de.toem.impulse.extension.log.xml.XmlLogReader.parseLogs(XmlLogReader.java:155) de.toem.impulse.extension.log.abstrac.AbstractLogReader.parse(AbstractLogReader.java:222) de.toem.impulse.serializer.AbstractParsingRecordReader.read(AbstractParsingRecordReader.java:117) de.toem.impulse.serializer.AbstractRecordReader.read(AbstractRecordReader.java:204) de.toem.pattern.element.Element$1.execute(Element.java:1067) de.toem.eclipse.hooks.actives.EclipseActives$3.run(EclipseActives.java:73)